Alexandr Poltavsky
Software Developer
Location: Russia, Moscow
poltavsky.alexandr@gmail.com
Blog
Github
Shadertoy
Twitter
atomic_data: A Multibyte General Purpose Lock-Free Data Structure
- Introduction
- Compare-And-Swap
- Load Linked/Store Conditional
- Evil Number One: the ABA
- Evil Number Two: Lifetime Management
- atomic_data
- Memory Ordering Considerations
- Usage (API)
- Exception safety, limitations and other issues
- Code Samples
- Performance Tests
Perhaps every article on lock-free programming should start with a warning that it's extremely hard to do right. There are certain subtle effects that lead to hard-to-catch bugs. Also, in an attempt to deal with it lock-free data structures and algorithms quickly become monstrous and entangled. Is it possible to keep everything simple and avoid bugs at the same time? We'll talk about it.
This article discusses two major problems in the lock-free Universe: the lifetime management problem and the root cause of the ABA. Also we will describe a relatively new lock-free data structure atomic_data. It solves the above two problems and offers a general enough approach to serve as a foundation for robust lock-free algorithms. In short, you wrap your data in atomic_data and by using its read and update methods you get transactional semantics of operation under any number of threads. You can have a megabyte array for example and it will still work. All of the code with a Visual Studio and Android Studio projects and some samples is available on GitHub.
As a reminder, there are three levels of guarantees: wait-free, lock-free and obstruction free. Wait-free is the strongest: operations on shared data basically never fail. This could be achieved, for example, when reading and updating is a single atomic operation. Lock-free assumes that some operations may fail, but progress is guaranteed in a fixed number of steps. And finally obstruction free means progress under no contention from other threads.
There are two major primitives/ways for doing lock-free programming: CAS (compare and swap) and LL/SC (load-linked/store-conditional. These are RMW ( Read-Modify-Write ) operations, but they are not equivalent. Also important is the fact that these operations acquire additional semantics when operating on pointers.
CAS (Compare-And-Swap)
CAS is an indivisible operation ([lock] cmpxchg instruction on x86) that compares an expected value at a memory address and replaces it with a desired value, on fail it returns the current value. Using CAS you could implement things like an atomic increment and basically any other atomic arithmetic operation.
But it gains additional meaning when used on pointers. Using CAS on a pointer could also be viewed as a rename with a check. Actually rename is the way you do atomic file modifications in Linux (rename system call is atomic if on the same device). Also important is that it establishes an equivalence relationship between the pointer and the data it points to. In the section on ABA we'll see how it plays out.
CAS provides the lock-free level of guarantee.
LL/SC (Load Linked/Store Conditional).
LL/SC operates with the help of a link register (one per core). By doing a special read (lwarx on PowerPC, ldrex on ARM) the link register is initialized. Any processing is then allowed and finished with a conditional store (stwcx on PowerPC, strex on ARM).
LL/SC is orthogonal to CAS because it's not comparing anything. It is also more general and robust. But it requires more work from the OS developers: on context switch a dummy conditional store is necessary to clear the reservation. This also could manifest itself under heavy contention: LL/SC could theoretically become obstruction free (CAS is always lock-free because at least one thread will always succeed).
Now to the evils that hunt lock-free programming. Here is a picture of a stack and two threads doing work.

Evil Number One: the ABA
As we observed above, CAS on pointers ties together the pointer and the data it points to. ABA happens when our idea about this relationship no longer holds true: the state of shared data has changed (broken invariant) and we are unable to detect that with the CAS (LL/LC is immune to this problem) on the pointer, because that pointer might have been deleted and reallocated again. The ABA results in lost data and invalid data structure.
ABA can be solved in a number of ways: GC, hazard pointers, versioned pointers. Another solution is to make the data immutable in a strict sense. I mean, not only the data itself is constant, but also the address it occupies is unique. This is the way a versioned pointer works: we add a version tag to the pointer and this has the effect of increasing the address space.
It really helps to think about lock-free operations in the following way: as soon as we touched any piece of shared data - we initiated a transaction, and the transaction should behave as stated by the ACID rules.
As is written above, LL/SC doesn't suffer from ABA because on context switch the reservation is cleared.
Evil Number Two: Lifetime Management

In the above image the cat is an object. The object lifetime problem in multithreaded programming is fundamental because at any point in time shared data could be accessed by a thread. Using exclusive locking is going to work but kills performance. Also GC, hazard pointers or using shared_ptrs can help, but they all are not ideal. GC needs a stop-the-world pause, hazard pointers require checking all threads, reference counting is a performance hit and might break out of control.
In no way this is the exhaustive description of lock-free programming issues, but these two are the most important. For linked data structures there is also a delete problem and we'll cover it later.
Now it is time for me to introduce atomic_data that is a good compromise between having a lock-free data structure and avoiding the ABA and lifetime issues.
atomic_data: A Multibyte General Purpose Lock-Free Data Structure
atomic_data is a variant of RCU (Read-Copy-Update). Actually, at first I didn't know that fact, but then, while exploring, I came upon this page by Paul McKenney. Also you can read about how the RCU is used in the Linux Kernel. After studying different implementations I came to a conclusion that atomic_data has a novel design and therefore has some value for the community. But if you feel like that was already done before - feel free to leave a comment.
The one important aspect that divides RCU techniques is in how reclamation of used memory is done. We need a grace period - when data is no longer accessed by threads - to do cleaning. This way we solve the lifetime management problem but not necessarily the ABA problem.
atomic_data is a template that wraps any data structure. There is a static preallocated circular lock-free queue of this data of desired length. C++ rules for templates and static data makes it one instance per data type. The following illustration will make it easier to understand.

During operation the update and read methods are being called that accept a functor (a lambda) as a parameter provided by the user. It atomically allocates an element from the circular lock-free queue, makes a copy of the current data and passes it to the functor. After the functor finishes, the update method tries to do CAS on the pointer to current data. In case of a failure the steps are repeated. On success the now old data element is being atomically returned to the circular queue. There is also an update_weak method that doesn't loop and returns a boolean.
So how do we avoid reusing used data and the ABA problem? That's where atomic_data differs: we use a backing multi-producer/multi-consumer queue and introduce a synchronization barrier. This sync barrier creates a "time out" during which atomic_data waits for old reads and updates to complete, no threads are touching data. But does it mean that readers are also blocked from reading data during that period? Here is a nice hack: the backing array for the queue is double the size that makes possible to use two atomic counters to watch for the data usage. This allows reading to be independent of the sync barrier and be wait-free (read the code for more details). So reading is never blocked.
When I got the idea for the design of atomic_data I had to choose how to implement a lock-free multi-producer/multi-consumer queue. I didn't suspect that doing this right is extremely difficult! I ran into every possible concurrency bug. There were three candidates in the end: two MP/SC queues with a single-threaded broker in between, a MP/MC queue requiring DCAS (Double CAS) to fight overrunning and finally a MP/MC queue with a sync barrier (I think I need to blog about it in a different post). After testing the best implementation was the queue with a barrier: it had a simple design, it worked very reliably, it didn't require DCAS and finally it showed good performance.
Memory Ordering Considerations
The cores of most modern CPUs are out-of-order (multi-core systems are out-of-order by definition). That means we have to consider the model of execution of our code. When it comes to memory we are dealing with a memory model. Another form of out-of-order execution is the reordering of memory operations. For example, Intel processors can reorder a store followed by load, but not a load followed by store. In that regard Intel CPUs are strongly-ordered. On the other hand ARM cores are weakly-ordered and can reorder both store-load and load-store operations.
Also the compilers themselves are capable of doing optimizations with reordering of instructions. To deal with it on both the hardware and software level C++11 introduced a C++ memory model. First, it has the notion of a data race - reading and writing the same memory location from different threads. To deal with data races atomic_data uses std::atomic data type from C++ standard library. Second, the C++ memory model introduces the concept of a memory order and defines them: relaxed, acquire, release and sequentially consistent. The seq-cst memory order is the strongest but also pessimistic in terms of possible optimizations. If you want more details, I really suggest you take some time and read the Jeff's blog and watch Herb Sutter's talk.
When we use standard synchronization primitives like mutexes then we don't usually have to think about memory ordering, because it's done for us implicitly. But when doing concurrent programming using RMW by hand we take full responsibility enforcing correct ordering on different platforms. For that the methods of the std::atomic data type take a memory order parameter.
To test the correctness of atomic_data operation I used an array of some size and the task was to find the minimum element and increment it. Given the right size of the array, the number of threads and the number of iterations for each thread the result should be that every array cell contains the same number: iterations * number of threads / array size. For example, 4 threads each doing 8192 increment iterations on an array of size 256: the entire array must contain the number 4*8192/256 = 128 in the end.
For the first draft of atomic_data every atomic operation was using relaxed semantics just to see what happens. Guess my surprise when on my 2 Core Intel machine the test was successful! What happened? Where is the memory ordering hell? This was my first revelation into strongly ordered CPUs. As Jeff Preshing mentions, on x86 the locked instructions act as memory barriers themselves. Also using static globals for the queue didn't left much opportunity for the compiler reordering of the source code.
But that's not the end of the story. The next in line for the test was my Samsung Galaxy S5 CPU: a 4 Core ARM. I created a simple project using Android NDK (thanks Google the C++ compilers are up-to-date and everything works, though some reading and googling might still be necessary ) and fired it up. BAM! Several thousand increments were missing! Nice, I was looking for this. Actually, I really advise you to get the Android Studio project for atomic_data and comment the two atomic_thread_fence calls there. After that fire it up on your smartphone, see the missing counts and then try to place the fences in the code yourself. The puzzle is - using the minimum number of fences achieve correct behaviour.
Observing the memory operation's reordering in the act was a nice experience. Gradually I got the intuition for what happens and solved the problem. It took me just two release fences. Here I'd like to mention the following observation: if a thread reads a variable that's behind a release barrier, it means all the memory stores before the observed value has reached the memory. I mean, if your reads are dependent then you can skip having an acquire fence. Actually, that is what you can read about in Jeff Preshing's post ( a->b ), where he also mentions that it is not true for Alpha CPUs.

Usage (API)
The greatest advantage of atomic_data in comparison with other lock-free techniques is the easy of using it. atomic_data is a template that wraps your data structure. It can be anything, the only requirement for it to be copyable and default constructable.
You have two basic methods to read and modify your data. The read method takes a functor that has a single parameter of a type "pointer to data structure type" that points to the latest version of the data and returns whatever the passed functor returns:
struct mydata {
int a;
float b;
double c;
};
atomic_data< mydata > mydata0;
//you can optionally add a second template parameter that sets the backing queue size
//making it equal 2 * number of threads is usually a good guess
//reading and returning field a
auto result = mydata0.read( []( mydata* data ) {
return data->a;
} );
The same thing is for the update, except it takes a pointer to a copy of the current data and returns a bool indicating whether you want for the update to happen or not. Data is updated atomically.
//atomically updating the data
mydata0.update( []( mydata* data ) {
data->b = data->b + 1.0f;
data->a++;
return true;
} );
You can read the source code of atomic_data on GitHub. It is a single header file and is just 300 lines of code. The simplicity of its implementation is another great plus.
Exception safety, limitations and other issues
The read and update methods - the workhorses - are exception safe. They employ RAII techniques to maintain invariants. There is also static initialization which calls new to fill the queue and destructor of atomic_data calls delete. Nothing is done there to guard against exceptions.
Special attention should be paid to the fact that atomic_data::update method is not reentrant, because you might hit a barrier and a second call to update will spin forever. atomic_data::update_weak on the other hand is reentrant. Though you should keep in mind that in no way two recursive calls to this method creates a transaction. Those are going to be separate updates.
You might rightfully ask if atomic_data is really lock-free since it has a sync barrier. Actually, if you think about it for a moment, due to limited computer memory some synchronization is unavoidable no matter what lock-free technique you use. Whether it be a GC pause or a check of all other threads or reference counting or something else. Reference counting and LL/LC to get around ABA might seem like a perfect match, but reference counting brings its own problems to the table. atomic_data is a good compromise and its flexible because you can adjust the length of the queue. Also a sync barrier helps uncover bugs earlier.
By the way what the length of the backing queue should be. From my tests it seems like 2x number of threads is quite enough. Actually atomic_data works even with the queue of length 1 (which I was surprised to find out). Nothing prevents from making the queue longer and offset the cost of the synchronization events.
Another often cited feature of true lock-free data structures is the tolerance to thread killings or suspensions. I am a bit confused by this argument. After all we are creating programs under the assumption of documented behaviour from the OS and hardware. We rely on fair scheduling policies from the OS and no spurious kill signals or suspensions should happen. And threads are not inferior to processes in any way. The only real issue is preemption and the picture below provides a Concurrency Visualizer graph of thread scheduling.

Here is the pic without drawing.
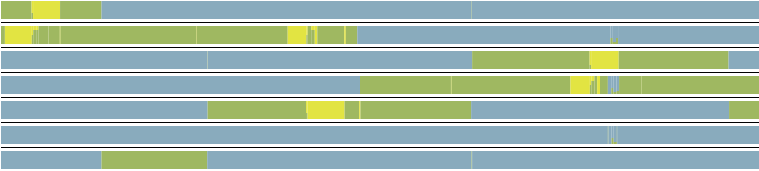{kind=link}
If it becomes a real problem in your program then you can increase the size of the queue. But from my tests it was never an issue and performance results speak for themselves (some numbers are at the very end).
Code Samples
Increments/Decrements of an Array
Now comes my favorite part because the design of atomic_data allows to create really cool things. Let us start with a test that was already described above (Memory Ordering part): a number of threads look up the minimum value in an array of some size and increment it. By the end of execution we expect all array cells to contains some know number.
const size_t array_size = 64;
const unsigned threads_size = 8;
const unsigned iterations = 81920;
//here comes the array, we can use any size, atomic\_data's read and update
//methods make the behaviour transactional
struct array_test {
unsigned data[ array_size ];
};
//an instance of atomic_data, queue is 2x threads_size
atomic_data<array_test, 2*threads_size> atomic_array;
//called by each thread
void update_array() {
//update, we are given a copy that we should update (RCU)
atomic_array.update( []( array_test* array_new ) {
unsigned min = -1;
size_t min_index = 0;
//look up the minimum value
for( size_t i = 0; i < array_size; i++ ) {
if( array_new->data[i] < min ) {
min = array_new->data[i];
min_index = i;
}
}
array_new->data[ min_index ]++;
//tell update that we are good to go
return true;
} );
}
At the end of execution every array element must be equal threads_size*iterations/array_size = 10240. Check out the code for this example on Github.
There is also an Android Studio project with this test and you can observe the effects of memory ordering on the result (try removing std::atomic_thread_fences in atomic_data.h) if you run it on a smartphone with a weakly ordered many-core processor (like ARM).
One thing to remember though is that atomic_data guards only the data it holds. If inside the update method the code updates some other global or captured data - that's gonna bite.
Lock-Free std::map?
The design of the atomic_data makes it really easy to turn any data structure into a concurrent one. All we need is to wrap it in atomic_data and use provided read and update methods to access it.
atomic_data< std::map<key, value> > atomic_map;
atomic_map.update( []( auto *map_new ) {
map_new->insert( { key, value } );
return true;
} );
auto it = atomic_map.read( []( auto *map ) {
auto it = map->find( key );
return it;
} );
Here is an example. Long time ago Andrei Alexandrescu offered such a map in his article. This one is definitely better.
Yes, it works. But the cost of copying makes it slower than using a mutex unless the access pattern is mostly reading. Actually for an atomic_data< std::vector > the story is different: vector can skip memory allocation on copying and it makes it quite fast. Try it on your machine.
atomic_data as a Container Element
atomic_data is copyable and movable and it can be used as a container element.
std::vector< atomic_data<int> > vector{ some_size };
vector[0].update( []() { .... } );
auto result = vector[0].read( [](){ .... } );
std::sort( begin( vector ), end( vector ) );
Here is a sample.
Concurrent Singly Linked List with Arbitrary Access
This is where atomic_data comes to its full glory. Compared to Herb Sutter's solution it doesn't require any special support from the std::atomic library, no need for Double CAS, no ABA and you can safely store iterators to list elements and dispose of them when necessary.
Here is the basic structure:
template< typename T, unsigned queue_length > struct atomic_list {
struct node;
using atomic_node = atomic_data<node>;
using node_ptr = std::shared_ptr<atomic_node>;
struct node {
bool lock;
T0 data;
node_ptr next;
};
...
};
Basically it's a list of atomic_data objects and the next pointer is wrapped in shared_ptr.
When we talk about lock-free linked data structures there is one particular problem they suffer from: the deletion problem. The drawing below describes it quite good.

Easy to get orphaned data. The easiest solution is to lock the node before deleting it. atomic_data here really helps. It allows for the atomic modification of all of the members of the node and makes implementation really clear and short. As a result we can write code like this:
//create an instance
atomic_list<int> atomic_list0;
//insert at the beginning, get iterator to the result
auto it = atomic_list0.insert( value );
//getting to the data under concurrency
auto value = it->read( [](auto* data) { return data->value; }
//removing
for( auto it = atomic_list0.begin(); it; ++it ) {
//*it returns a ref to atomic_data
if( (*it)->value == search_value ) {
//note the weak suffix, we can't be sure that an element is not locked
auto r = auto atomic_list0.remove_weak( it );
}
}
//iterating
for( auto& element : atomic_list0 ) { ... }
Here is an example to test the correctness: we prepopulate an instance of atomic_list with array_size number of elements. Then we launch threads that perform equal number of insertions and deletions at random positions. At the end we expect the list to remain the initial size. Get a look at the code on Github.
UPDATE. After thinking about it more I realized that there is no escaping of reference counting as you move through the list (you need nodes alive), and it essentially means hand-over locking. So in case you have a lean shared_ptr (to avoid DCAS) you just need to place two locks on the nodes, do the job of deleting or adding (adding needs a single lock), and be very accurate with shared_ptrs, because you going to have a mismatch between the number of shared_ptrs and reference counters, basically you'll have to add a release() method to a shared_ptr. That's all for a concurrent singly linked list.
Performance
So what about efficiency of atomic_data. Is it all worth learning about it? I say firm yes. The baseline was a bare mutex locking all reads and updates: the same interface as with atomic_data but no copying, no queues, just simple locking.
There are three basic cases: updates and zero reads, equal number of update and read calls, and reads prevailing over updates. Also important is the size of guarded data.
| OS | Windows 7 2 Core AMD VS2015 | Android 5 4 Core ARM NDK r12b, gnustl | ||||||
|---|---|---|---|---|---|---|---|---|
| data size | 1 | 8 | 64 | 256 | 1 | 8 | 64 | 256 |
| many updates zero reads | 110 220 | 160 290 | 300 500 | 750 1000 | 570 150 | 380 150 | 1000 250 | 1600 480 |
| many updates many reads | 130 250 | 210 290 | 580 510 | 1400 1200 | 330 150 | 890 170 | 1400 310 | 2400 700 |
| many updates 20x more reads | 280 300 | 690 620 | 3500 2000 | 13400 6800 | 720 165 | 1750 215 | 7000 800 | 25000 2700 |
| red background - mutex wins, green background - atomic_data wins | ||||||||
To get the numbers I used the array increments/decrements sample - the first in the Samples section above. These are milliseconds but they are relative just to compare the performance with the baseline std::mutex case. The first line is for the mutex, the second is atomic_data. The queue size for the atomic_data was 2*threads_size and threads_size = 8.
You can see how good the std::mutex on Windows 7 is (it was compiled with Visual Studio 2015). Looking up on the Net it seems the implementation busy spins for a while (optimistic logic) and the fact, that increasing the data size changes the situation, supports that guess.
On Android the timings are especially sweet. The only problem was that Android dynamically adjusts priorities and the mutex version had quite different timings (but always worse that atomic_data).
The results show that atomic_data is quite competitive even with it copying the data on every update. But we need more testing and I ask for your help here. Clone or download the GitHub repo and run the tests on your machine. atomic_data works both on 32-bit and 64-bit machines.
You're a hero if you've read all of the article.